Making my content accessible One Ruby script at a time Hey, everyone.
Thanks for joining me today to hear about my adventures making my content more easily accessible to everyone, starting with one Ruby script
A bit about me, for those who don't already know me:
My name's Jason, but everyone knows me by my last name, Gedge.
I'm currently unemployed (voluntarily) and recovering from burnout, but that's a topic for another day.
I've barely written Ruby since 2020, so I leaned on Cursor / Claude to help me out.
I'll touch on why I took this approach, my experience using AI to help me with that — the good and the
bad — along with interesting tidbits I learned along the way.
Data sovereignty I want to own my content
Simplicity I want to keep it simple Primarily plaintext, with a sprinkle of components for anything fancier.
Accessibility Easily available to everyone A website is easy to distribute to everyone
With a bit of effort, I can also make it accessible to everyone (maybe Google slides works well for screen readers, who knows)
And I get access to all kinds of fun web tech!
Consistency All presentations look and work the same way Can consistently brand my slides
Social handles easy to update, if needed
This does mean there will be some potential differences from when the presentation was given,
but I'm hoping to ensure all content on my website is versioned for anything substantile.
Learning An opportunity to play around with some AI tech AI is here, and I haven't heavily used it yet so I thought I'd give it a try.
Mostly just used autocomplete in Cursor until this.
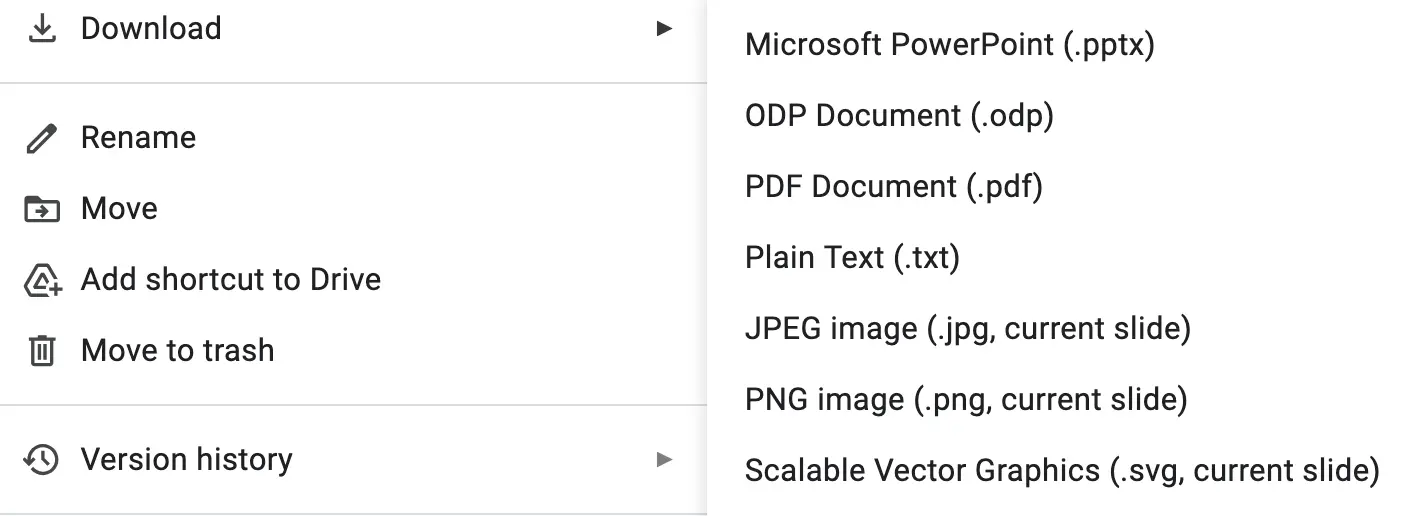
Fun I enjoy writing code, especially little scripts The download options for a Google Slides presentation.
PowerPoint felt a little too proprietary
Plaintext would drop styles, images, and other formatting
PDF and image formats would also be difficult to extract text from
Naturally the only choice left was ODP
Open Document Format "An XML schema for office documents. Office documents include text documents, spreadsheets, charts and graphical documents like drawings or presentations, and other forms of documents." Open Document is, as its name suggest, an open standard for office documents.
ODP is specifically a presentation format.
Can be a single XML file, or a
package
consisting of XML files, and perhaps other supporting files (like images) in a ZIP file archive
├── Pictures
│ ├── 10000000000002A80000017F6C1C798C.jpg
│ ├── 1000000000000438000002A33ABEA1C5.jpg
│ ├── 100000000000050000000355A29595A0.jpg
│ ├── 10000000000006AB00000800BEE43A5C.jpg
│ ├── 100000010000006400000080A8DBB75F.png
│ ├── ...
│ ├── 10000039000001E00000016AEBE3056B.gif
│ └── TablePreview1.svm
├── content.xml
├── meta.xml
├── settings.xml
└── styles.xml
Here's what an extracted ODP file looks like.
content.xml is the main presentation file, containing all the slides and their content.meta.xml contains metadata about the presentation, like its title and description.settings.xml contains settings for the presentation, like the grid lines and the selected page.styles.xml contains the styles for the presentation, like the font and color scheme. We won't get into the nitty gritty of the XML files, but you can read the specification if you're curious.
I'll show a few interesting bits though!
<office:automatic-styles >
<style:style style:family =" drawing-page" style:name =" dp1"
<style:drawing-page-properties
presentation:background-objects-visible =" true"
presentation:background-visible =" true"
presentation:display-date-time =" false"
presentation:display-footer =" false"
presentation:display-page-number =" false"
/>
</style:style >
</office:automatic-styles >
First, even though there's a separate styles.xml file, those are more base/theme styles.
You still need to use these styles, otherwise you may lose styles.
This specific style is known as a "drawing page" style, which affects the entire slide (often the background)
Other styles for text, paragraphs, graphics, tables, lists, and much more.
<office:body >
<office:presentation >
<draw:page
draw:master-page-name =" TITLE"
draw:name =" page1"
draw:style-name =" dp1"
presentation:presentation-page-layout-name =" AL1T0"
>
<!-- Slide content -->
</draw:page >
</office:presentation >
</office:body >
Contained in the office:body and office:presentation elements is the actual presentation.
draw:page is the main container for each slide.
Can reference a layout from the main theme
<draw:frame
draw:name =" Google Shape;63;p13"
draw:text-style-name =" P2"
presentation:className =" title"
presentation:style-name =" pr1"
svg:height =" 2.5cm"
svg:width =" 22cm"
svg:x =" 1cm"
svg:y =" 5cm"
>
<draw:text-box >
<text:p text:style-name =" P1"
<text:span text:style-name =" T1" text:span >
</text:p >
</draw:text-box >
</draw:frame >
Every slide can be composed of many elements, but Google Slides typically emits frames in its ODP export.
draw:frame is just a container for content.
In this example, it contains a various textual elements.
If you put a border on a text box, it actually emits a draw:custom-shape element instead of a text box!
Note the cm values too. I'll talk about how I handled those later!
<presentation:notes draw:style-name =" dp2"
<draw:page-thumbnail draw:style-name =" gr2" svg:height =" 11cm" svg:width =" 19cm" svg:x =" 1cm" svg:y =" 2cm"
<draw:frame draw:text-style-name =" P7" svg:height =" 11cm" svg:width =" 15cm" svg:x =" 2cm" svg:y =" 12cm"
<draw:text-box >
<text:p text:style-name =" P1"
<text:span text:style-name =" T1" text:span > about the slide
</text:p >
</draw:text-box >
</draw:frame >
</presentation:notes >
Also included in draw:page are the speaker notes
There's also potentially styles in here, but I mostly ignored them when exporting.
There's also a thumbnail element, but I ignored that one too!
<draw:custom-shape
draw:style-name =" gr9"
draw:transform =" skewX (-0.00035) translate (3cm 2cm)"
svg:height =" 6.5"
svg:width =" 2cm"
>
<draw:enhanced-geometry
draw:enhanced-path =" M 0 ?f5 L ?f8 ?f5 ?f8 0 ?f9 0 ?f9 ?f5 ?f14 ?f5 ?f7 ?f13 Z N"
draw:text-areas =" ?f8 0 ?f9 ?f12"
draw:type =" ooxml-downArrow"
svg:viewBox =" 0 0 0 0"
>
<draw:equation draw:formula =" min(logwidth,logheight)" draw:name =" f0"
<!-- ... -->
<draw:equation draw:formula =" logwidth" draw:name =" f14"
</draw:enhanced-geometry >
</draw:custom-shape >
One other interesting piece to implement were geometric shapes.
Essentially SVG, but not exactly.
Paths are defined by formulas based on bounding boxes and other "dynamic" values
There's so much more, so check out the spec if you're curious.
It was pretty overwhelming too, so I thought this would be a great opportunity to play around with AI.
Let's create a plan for a script that can read in an open document presentation file and produce a set of MDX (markdown + react) files for each slide (for an example of an existing presentation, see @(../src/pages/presentations/2024-05-28_static_analysis_of_ruby.mdx).
## Requirements - This should be a simple script. Keep the code short and simple, and all in one file.- Read in an ODP file and produce an MDX file.- Script should ask for the presentation date in the ` YYYY-MM-DD ` format (clearly specify this when prompting the user too).- Look for a presentation name in the file. If one can't be found, prompt for it.- The filename should be an "underscored" version of the date and title. For example, if the presentation date is July 17th, 1987 and the presentation is titled "Some cool stuff", the filename would be ` 1987_07_17_some_cool_stuff.mdx ` (remove punctuation and any non-alphanumeric characters when producing the filename).- Images should be placed in ` ./src/static/img/presentations/ ` , under a folder with the same name as the file (without the extension).module Draw class Frame < Base
include Mixins ::PositionableElement
def to_mdx
style_object = generate_positioning_style_object
<<~MDX
<div style={#{ style_object} }> #{ content} </div> MDX end
register_for " draw:frame"
end
end Using REXML to parse the XML files
Every XML node I care about represented by a class, which registers itself with a base
Each class has a method to convert itself to MDX
This actually worked really well out of the box.
Main problem: WAY too much output
After combing through the output, I realized there was opportunity to reduce the output size.
To do so, I came up with some heuristics.
Convert cm → percentage <----------- 27cm ----------->
┌─────────────────────────────┐
│ <------ 10cm ------> │ x = 4cm / 27cm
│ 4cm ┌──────────────────┐ │ ≈ 14.8%
│<---->│ │ │
│ │ │ │ width = 10cm / 27cm
│ │ draw:frame │ │ ≈ 37.0%
│ └──────────────────┘ │
│ draw:page │
└─────────────────────────────┘
This one was interesting
Not necessary to reduce output size, but helped with the visual appearance.
CSS has a cm unit, but everything was a little too small when I did a 1:1 conversion.
Ended up looking for page dimensions in the various XML files, and then converting to percentages.
A lot of slides have content that is centered, but no indication of that in the XML.
Ended up checking for pages with a single frame element that looked to be mostly centered
If so, drop the <div> wrapper and set the slide's layout to centered.
Combine adjacent spans <span className =" t12" span >
<span className =" t12" span >
<span className =" t13" span >
<span className =" t12" span >
<span className =" t12" span >
<span className =" t12" span >
<span className =" t12" span >
<span className =" t12" span >
Typical of WYSIWYG editors, they generate a lot of redundant spans, because that's the easiest thing to do.
Specifically though, I only combine them if they have the same style
Significantly reduced the output size.
Remove empty/unused styles CSS was MASSIVE on my first pass (hundreds of lines, each having A LOT of properties)
More than half the output (in bytes)
Lots of redundancy, and mostly unused.
Flag styles as used and only output those.
Drop properties I didn't care about / looked like defaults.
Utility classes .t1 { font-size : 12 pt ;
font-weight : normal ;
font-decoration : none ;
color : #000000 ;
}
.t2 { font-size : 14 pt ;
font-weight : bold ;
font-decoration : none ;
color : #000000 ;
}
.t3 { font-size : 12 pt ;
font-weight : bold ;
font-decoration : none ;
color : #000000 ;
}
.c1 { font-size : 12 pt ;
}
.c2 { font-size : 14 pt ;
}
.c3 { font-weight : bold ;
}
Noticed many styles overlapped a ton (same properties, especially font size)
Break down styles with many properties so that every property is a single class
Kind of similar to how Tailwind approaches CSS
Okay, let's try converting another presentation to MDX.
Note: I've only verified the script works for this presentation, but have never seen the result!
Okay, I mentioned I'd talk a bit about my experience with AI.
It did a pretty good job at getting me started, but after that I generally had a poor experience
I'll comment more on this experience later, but full disclosure: I didn't provide many guardrails.
I didn't ask it to write tests.
No Sorbet or types
I'll get one of my favourite TV characters — David Rose — to help express my frustration.
Continued to run the wrong validation script
Every time I asked it to validate its changes with the script we were working on, it always did the wrong thing.
For example, it would always cd into the wrong directory, or run the script incorrectly
Mostly resolved after I figured out how to incorporate rules
Hardcoded values
I gave it some XML files from an OpenDocument presentation to help it infer structure, but it always wanted hardcode values (even after adding rules)
Imagine doing test-driven development where you write functions with hardcoded results for all the tests. Sure, they pass, but that's not what you want.
Emphasizes the shallowness of LLMs.
Poor design and implementation
It mostly got the job done, but with a lot of redundancy and unnecessary "copy pasta".
Until I gave it significantly more guidance, there wasn't really a ton of structure to the code (flat, few modules, large methods)
Seems like it was just focused on getting the job done, nothing else.
I removed nearly 2k lines of code by refactoring (That's more than half the project)
Maybe it struggles with Ruby, or maybe I'm bad at writing prompts.
If the latter, maybe have to work on my communication skills.
If I have to adapt to some subset of natural language to get the tool to work, I'd consider that bad UX.
Don't get me started on "you're absolutely right" and other sycophantic responses.
I'll try some other tools in the future. I've heard good things about Claude Code.
Also, will try in a more constrained environment (tests, types, and so on).
If that doesn't go well, I suspect I'll stick to doing a lot of my own stuff, and maybe use AI for a few things...
Thanks for listening!
❤️ ❤️ ❤️ ❤️ ❤️ ❤️